If all you want is the code, then head over to the repo.
This is the second part of a series where we’re building an online game in Rust from scratch. In the first section we went through an overview of how websockets work, and the steps towards connecting to a server, though the code we wrote only dealt with SHA-1 portion of the initial handshake process. In this article we’re going to implement the Base64 portion of that same process, and once that’s done we can start on the server itself.
The Base64 algorithm involves taking data and converting it into a string of characters, each represented by 6-bits. It’s a method used to transport binary information using a subset of ASCII which should readable by almost every computer system out there. You may have seen it used with images and possibly other places, but aside from that it’s just a way to represent data.
The question we’re going to be asking, and the answer we’ll code up, is how does Base64 work? Say that we’re given an ASCII string of “ABCD” and are asked to convert it to Base64, how would we go about doing that?
The steps, broadly speaking, that we’d take would look like the following:
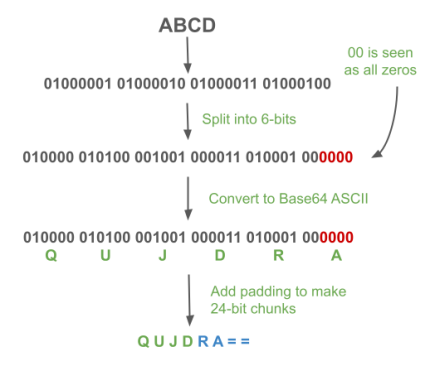
The algorithm can be summarized as follows:
The simplicity of these steps hides the complexity we’ll be covering, but they are a good starting point for creating our own Base64 module. We’ll be doing this from scratch, the same as the last section of this series, while covering a few other topics along the way, including:
Keep in mind what follows is not meant to be a comprehensive tutorial, but as a guide for people looking to follow someone else’s learning process.
And with that, let’s get started with our setup.
First we’ll want to create a new Rust project and a file called base64.rs alongside main.rs. In base64.rs we’ll create a public Base64 type, and way to create a new instances of that type.
// base64.rs
pub struct Base64;
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
}Above this we’ll create a constant variable which provides our character set, or the 64 characters which define Base64.
// base64.rs
const BASE64_CHARSET: &[u8; 64] =
b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
pub struct Base64;
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
}Next, we’ll create two functions with similar signatures for both encoding and decoding.
// base64.rs
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn encode(&mut self, input: &str) -> Result<String, Base64Error> {
Ok("".to_owned())
}
pub fn decode(&mut self, input: &str) -> Result<String, Base64Error> {
Ok("".to_owned())
}
}The return values on each are placeholders to avoid compiler errors and will be replaced later. If you’re not familiar with Result and the use of Ok, then check out this article which I wrote as a companion piece to this one.
Now, let’s pop back to main.rs and create some test data and do something a little new:
// main.rs
mod base64;
use base64::Base64;
fn main() {
let original = "TESTING";
let mut base64 = Base64::new();
let encoded = base64.encode(original).unwrap();
let decoded = base64.decode(&encoded).unwrap();
println!("Original: {}", original);
println!("Encoded: {}", encoded);
println!("Decoded: {}", decoded);
assert_eq!(original, decoded, "Failed");
}If you haven’t seen an assert statement before, they’re often used in tests to check if a value is as expected. In our case we expect the original and decoded variables to be equivalent, and hence we use the assert_eq function. There is also an assert_ne for checking if something is not equal. That being said we could use the basic assert function and do:
assert!(original.eq(decoded.as_str()), "Original and decoded are not equal!");I normally don’t leave asserts in my code like this and instead put them in separate tests. To do that we’ll take a brief detour into writing tests with Rust, so if you already know how to do this, skip to the next section.
I’m only going to go over unit tests, which in Rust are often found alongside the code, generally at the bottom of a file. These deal with single functions, components or modules, like our base64 module. To write one we first add a macro and a module below our main function:
// main.rs
#[cfg(test)]
mod tests {
}If you haven’t heard of macros, they’re a way of applying changes to the code prior to being compiled. This can help you save time writing boilerplate code, and allows you to easily apply functionality to existing code.
In our case, we add #[cfg(test)], which modifies the mod test block in such a way to add the necessary boilerplate and metadata the compiler will need to run our test. The official docs give a good overview of what is happening, but later in this series we’ll go even more indepth when we create our own macros.
Inside this module we’re going to write a single test which does the same thing as we did in our main function above.
// main.rs
#[cfg(test)]
mod tests {
use super::base64::Base64;
#[test]
fn test_base64_encode_decode() {
let original = "hello world";
let mut base64 = Base64::new();
let encoded = base64.encode(original).unwrap();
let decoded = base64.decode(&encoded).unwrap();
assert_eq!(
original,
decoded.unwrap(),
"Original and decoded messages do not match"
);
}
}Almost everything here is the same aside from the use super::base64::Base64 line which providing us access to the base64 module. You’ll notice that this function also has a macro #[test], which is again doing a bit of modification to the function prior to compilation.
To run the test we only need to do the following:
cargo testAt this point the test will fail because we haven’t implemented our base64 module.
You can now remove the assert from the main function, but leave the rest so we can still get output when using cargo run.
You may not be satisfied with my hand wavy introduction to the macros above, and want to know more about just how these macros are changing things. You can actually check that using rustc, the Rust compiler.
First, try to run this at the terminal, assuming you’re in the root folder of your project:
rustc -Zunpretty=expanded src/main.rsIt will most likely give you this error:
error: the option `Z` is only accepted on the nightly compilerRust has three channels for development of the compile: stable, beta and nightly. I couldn’t find a satisfactory reason why we need to use nightly to expand macros, though some people in the Discord speculated it may be due to their unstable nature. Whatever the case may be, we’ll need to install the nightly build in order to do the next part. Assuming you’ve installed rustup, you can do the following:
rustup toolchain install nightlyThis might take a moment, but once done you can switch between the stable and nightly channels using:
rustup default nightly
rustup default stableFor most of what we’re doing, you’ll want to used stable, but for for now it’s nightly. After switching over you can now expand your code post macro using the same command as above. Note that addition of the –test which tells rustc to also expand the tests. Try running it without it and you’ll see it just the code.
rustc -Zunpretty=expanded src/main.rs --testThis should have printed out your entire program, including the the base64.rs as well as main.rs and your tests. Some of it you will recognize while other parts, like your print statements, will have change into things like this:
{ ::std::io::_print(format_args!("Encoded: {0}\n", encoded)); };This is because println!() is also macro, and it expands into std::io (standard library input/output) calls.
There are two types of macros in Rust, declarative, or macros by example, and procedural macros. The latter can be broke into derive, attribute and function-like macros, as per the linked docs.
Diving into macros is a whole other article or three, but just know that anything attached to a struct or enum that looks like #[ … ], or that’s a function with an exclamation point !, is a macro.
Now we did all this to look at the expansion of the macros within our test, so make sure you run it with the –test flag and then look at your mod tests. Here you can see that your original test function test_base64_encode_decode has been expanded into two separate functions:
...
pub const test_base64_encode_decode: test::TestDescAndFn =
test::TestDescAndFn {
desc: test::TestDesc {
name: test::StaticTestName("tests::test_base64_encode_decode"),
ignore: false,
ignore_message: ::core::option::Option::None,
source_file: "src/main.rs",
start_line: 30usize,
start_col: 8usize,
end_line: 30usize,
end_col: 33usize,
compile_fail: false,
no_run: false,
should_panic: test::ShouldPanic::No,
test_type: test::TestType::UnitTest,
},
testfn: test::StaticTestFn(#[coverage(off)] ||
test::assert_test_result(test_base64_encode_decode())),
};
fn test_base64_encode_decode() {
let original = "hello world";
let mut base64 = Base64::new();
let encoded = base64.encode(original).unwrap();
let decoded = base64.decode(&encoded).unwrap();
match (&original, &decoded) {
(left_val, right_val) => {
if !(*left_val == *right_val) {
let kind = ::core::panicking::AssertKind::Eq;
::core::panicking::assert_failed(kind, &*left_val,
&*right_val,
::core::option::Option::Some(format_args!("Original and decoded messages do not match")));
}
}
};
}I’m not entirely certain why this is the case, as it’s some specific to the way the compiler is organizing things, but there are few things we can note. The first function contains metadata along with a call to the second, while the second function is the one we wrote. I’d wager the first is just laying the framework for the compiler to give us proper feedback on running the test, but I can’t say for sure.
You might think that since this is just code expanded prior to compilation that we could replace it with the original, but in this case there’s a problem. At this point, if you want to following along, you can modify your project by copying and pasting the output from the terminal in your file(s) or create a second project with this expanded code.
In our expanded code, the first function, which contains the metadata, is assigned to the variable test_base64_encode_decode of type TestDescAndFn, and that name is the same as the function below. This will cause a naming conflict, but it can be fixed by changing the second function’s name slightly (I just added a 1) and then updating the call in the first section to reflect that change:
testfn: test::StaticTestFn(
#[coverage(off)]
|| test::assert_test_result(test_base64_encode_decode1()),
),Still, if you do this, and try to compile, you will run into errors like the following:
> use of unstable library feature 'panic_internals':
internal details of the implementation of the `panic!` and related macros.
add `#![feature(panic_internals)]` to the crate attributes to enableAs you can see, there are a number of likely unfamiliar functions being used in this expanded code. Many of these features are unstable, but that doesn’t mean they are necessarily unsafe, just that they may not be fully implemented or have unresolved issues or has not been tested enough to get the greenlight to move to stable.
To resolve these errors we need to add the necessary features at the top of main.rs:
#![feature(test)]
#![feature(rustc_attrs)]
#![feature(coverage_attribute)]
#![feature(panic_internals)]At this point it will run the test as normal, though it will throw some warnings about the unstable features we added being internal to the compiler. Normally, you’ll not be running nightly, nor using expanded macros in your code, but this was in the name of science, so yay us!
To recap, macros come in different styles, but for the most part if you see something of the form #[ … ] or foo!() then you’re dealing with a macro. The purpose of a macro is to simplify things which you do often by adding or modifying your code prior to compilation.
And with that detour out of the way, let’s start writing our Base64 module, starting with properly handling errors.
Let’s look at what we already have for our encode and decode functions:
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn encode(&mut self, input: &str) -> Result<String, Base64Error> {
Ok("".to_owned())
}
pub fn decode(&mut self, input: &str) -> Result<String, Base64Error> {
Ok("".to_owned())
}
}You’ll notice that we have a Result for both functions which says that if the function is successful we will return an Ok(String) and if it fails an Err(Base64Error). We’ve already got a placeholder for the former, but we’ve yet to discuss the Base64Error type. Again, if you’re not familiar with Result or unwrap then please check out this supplementary article which goes over both.
To better handle errors we’re going to implement our own error type, which will be represented by an Enum called Base64Error. This will cover invalid characters and potential UTF-8 errors.
use std::string::FromUtf8Error;
...
pub enum Base64Error {
InvalidCharacter,
Utf8Error(FromUtf8Error),
}We have added the FromUtf8Error struct to the top of the file, and applied it to our of Ut8Error. This is saying that it will take on the traits of the standand library errors, so we have those errors for free.
Now we’re going to implement Display for our enum, which will allow us to display specific messages based on the type of error. Display is a trait, which requires we implement the format (fmt) function.
use std::string::FromUtf8Error;
...
pub enum Base64Error {
InvalidCharacter,
Utf8Error(FromUtf8Error),
}
impl std::fmt::Display for Base64Error {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
...
}
}If you’re not familiar with traits, they are a way to define functionality, and are similar to interfaces in other languages, with some caveats. I’d recommend reading the docs for a more detailed understanding, but for now think of them as a way to say “this struct has this ability” and providing a guarantee you’ve implemented this. In the case of Display, it’s used to define how we’ll show information about something, that something being an error in our case.
This is done through Formatter which also works with traits like Debug. Say, for example, you have a struct which defines user information, and when you print this to the terminal you want it to display nicely formatted information, as opposed to the key-value pair sort of output you might normally get. To do that, you’ll need your struct to implement the Display type format, so that whenver you do a println!("{}", your_struct_instance) it’s correctly print out the details.
To do that with our Base64 error we add the following:
use std::string::FromUtf8Error;
...
pub enum Base64Error {
InvalidCharacter,
Utf8Error(FromUtf8Error),
}
impl std::fmt::Display for Base64Error {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
match *self {
Base64Error::InvalidCharacter => write!(f, "Invalid character in input"),
Base64Error::Utf8Error(ref e) => e.fmt(f),
}
}
}This match statement is a bit different than want we’ve seen before in that is matches on *self, which with the * looks oddly like a bit of C or C++ code playing with Python. What’s actually going on here is we’re dereferencing self, which at this point is a reference to the Base64Error instance. We could instead match on &Base64Error::InvalidCharacter => .., adding the &, which isn’t too much extra work, but this ends of being more tidy.
As far as the matching itself, for the first error we use the write! macro, while the second makes use of the existing error type in the standard library as imported above. At this point, everything should be working. Later we’ll be able to test that these error types are working as intended.
Finally, we’re going to do some actual Base64 stuff, following the four bullet points from the start of this article as our guide:
Creating this error type is done in the next section, and that if you’re following along here your code won’t work until we get that part done.
In the encode function add this setup code:
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn encode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut encoded = Vec::new();
let bytes = input.as_bytes();
let mut buffer: u32;
...
}
}The first variable, encoded will hold the final result of our encoding, while the second is the input in bytes as per this section’s header. The last is a buffer which is going to hold the part we’re currently parsing.
The choice of buffer is of note because it’s a 32-bit unsigned integer. When thinking about converting our input into a string of binary bits, you might think it’d be better to convert everything in one go by appending the bits to a string or adding them to an array. This would work fine for smaller input values, but the large they are the more memory we’ll need. Since all we need to is slice off 6-bits at a time and then convert them to them to their respective ASCII values found in the BASE64_CHARSET, we can just take what we need when we need it. By byteing off pieces and storing them in an unsigned 32-bit integer we’ll not only save space, but we can easily use bit shifting and logical operations, which are cheap with regard to CPU cycles.
The next step is to loop through these bytes, taking one 3-byte (if possible) chunk at a time.
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn encode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut encoded = Vec::new();
let bytes = input.as_bytes();
let mut buffer: u32;
for chunk in bytes.chunks(3) {
}
...
}
}For all but the last iteration we’ll have exactly 3-bytes. On the last iteration we may have 3, 2 or 1, depending on the input string. For example if try to encode ABCD we’ll be able to grab ABC with the first chunk, but we’ll only get D with the last one, which means one byte.
After we get a chunk, we’re going to check it’s length and fill our buffer accordingly:
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn encode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut encoded = Vec::new();
let bytes = input.as_bytes();
let mut buffer: u32;
for chunk in bytes.chunks(3) {
buffer = match chunk.len() {
3 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8) | u32::from(chunk[2]),
2 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8),
1 => u32::from(chunk[0]) << 16,
_ => 0,
};
}
...
}
}Again we’re dealing with match, just like in the last article on SHA-1. In this match statement we’re matching on 3, 2, or 1 bytes, with _ matching against anything else. This _ , or default branch, will never be reached since the the chunks function won’t return anything but 1, 2, or 3 bytes. Still, it’s required that we have covered all possible matches in order to please the compiler. All hail our compiler overlord.
The right side of these branches if going to be what we put in our buffer. What each of them is doing is cramming in our bytes from the right side, one byte at a time. In the first match branch it’ll put three bytes, or 24-bits, and then two bytes in the second and one in the last (non-default). We do this because later we need to take out 6-bits at a time, and these will overlap bytes which come from different letters. What we’re doing is concating them as bits and using the u32 as a place to stash them, as mentioned earlier.
To get an idea of what is happening, take a look at the program below, which can you run for yourself here:
fn main() {
let mut res: u32;
let a: u8 = 255;
let b: u8 = 8;
let c: u8 = 128;
res = u32::from(a) << 16;
println!("{res:b}");
res = res | u32::from(b) << 8;
println!("{res:b}");
res = res | u32::from(c);
println!("{res:b}");
}Here we take three numbers which in binary are 11111111, 00001000 and 10000000 and concat them together by shoving them into the u32 from the right hand side one at time, and then shifting « them left 16, 8 and then 0 bits, respectively.
The output from the program gives us this:
111111110000000000000000
111111110000100000000000
111111110000100010000000You can see the first byte shifted in all the way to the left, then the next byte and finally the last. We use the bitwise OR operator | to preserve the previous shifted in value. It’s essentially adding them, like this, which gives us b from the above code:
111111110000000000000000
000000000000100000000000
+ _________________________
111111110000100000000000Once done, we can start taking out 6-bits at a time.
Before we can get these 6-bit pieces from the buffer, we first record how many characters we plan on encoding:
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn encode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut encoded = Vec::new();
let bytes = input.as_bytes();
let mut buffer: u32;
for chunk in bytes.chunks(3) {
buffer = match chunk.len() {
3 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8) | u32::from(chunk[2]),
2 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8),
1 => u32::from(chunk[0]) << 16,
_ => 0,
};
let output_chars = chunk.len() + 1;
}
...
}
}Because we’re going 6-bits at a time through 24-bits (we ignore the last 8-bits of the u32) we loop through four times:
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn encode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut encoded = Vec::new();
let bytes = input.as_bytes();
let mut buffer: u32;
for chunk in bytes.chunks(3) {
buffer = match chunk.len() {
3 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8) | u32::from(chunk[2]),
2 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8),
1 => u32::from(chunk[0]) << 16,
_ => 0,
};
let output_chars = chunk.len() + 1;
for i in 0..4 {
}
}
...
}
}For each of these four iterations we need to determine if we’re converting everything to an ASCII value or if we’ve reached the end of our original input. As noted earlier, only the last chunk isn’t guaranteed to be 3-bytes, and if it’s not we’ll append an equal sign = as padding (discussed further below). That means most of the time output_chars will be 3, and the loop counter i will be less than it.
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn encode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut encoded = Vec::new();
let bytes = input.as_bytes();
let mut buffer: u32;
for chunk in bytes.chunks(3) {
buffer = match chunk.len() {
3 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8) | u32::from(chunk[2]),
2 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8),
1 => u32::from(chunk[0]) << 16,
_ => 0,
};
let output_chars = chunk.len() + 1;
for i in 0..4 {
if i < output_chars {
let shift = 18 - i * 6;
let temp = buffer >> shift;
let index = (temp & 63) as usize;
encoded.push(BASE64_CHARSET[index]);
} else {
encoded.push(b'=');
}
}
}
...
}
}Inside our conditional if i < output_char we shift the values out of buffer 6-bits at a time using the right shift » and then convert it to an integer. Here usize refers to the platform’s default size, which will likely be 64-bit or 32-bit. Let’s walk an example of how this works assuming we have a value of 101111110000100010000000 in our buffer.
let shift = 18 - i * 6;
This calculates the amount of the shift, which since i starts at 0 will be 18.
Next we have:
let temp = buffer >> shift;Given the 18 for shift, it means we take our original value and move everything right, dropping the bits on the right side, and giving us 101111 as all that remains.
let index = ((temp) & 63) as usize;
The next line makes use of 63, which is 111111 and it acts as a mask, removing everything from temp save for our number. The idea is we have another u32 which is 00….111111 and when you AND that with another number it’ll preserve only the rightmost 8-bits.
encoded.push(BASE64_CHARSET[index]);We take the index and find the corresponding ASCII character in the lookup we defined earlier.
Now, there’s an exception to this process, and that’s when we get to the end of our chunks. According to the Base64 specs it needs to be made from 24-bit chunks, but what happens if at the end of our data we don’t have enough bits left to round it out to 24? That’s where this line comes in:
encoded.push(b'=');In this case we add some padding in the form of equal signs to get us up to 24-bits. Depending on the initial input you might have 0, 1 or 2 of these equal signs.
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn encode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut encoded = Vec::new();
let bytes = input.as_bytes();
let mut buffer: u32;
for chunk in bytes.chunks(3) {
buffer = match chunk.len() {
3 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8) | u32::from(chunk[2]),
2 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8),
1 => u32::from(chunk[0]) << 16,
_ => 0,
};
let output_chars = chunk.len() + 1;
for i in 0..4 {
if i < output_chars {
let shift = 18 - i * 6;
let temp = buffer >> shift;
let index = (temp & 63) as usize;
encoded.push(BASE64_CHARSET[index]);
} else {
encoded.push(b'=');
}
}
}
}The entire process we’ve just covered is now repeated until we’ve run out of chunks, and then we convert the vector into a String and return it. That gives us the completed code:
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn encode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut encoded = Vec::new();
let bytes = input.as_bytes();
let mut buffer: u32;
for chunk in bytes.chunks(3) {
buffer = match chunk.len() {
3 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8) | u32::from(chunk[2]),
2 => (u32::from(chunk[0]) << 16) | (u32::from(chunk[1]) << 8),
1 => u32::from(chunk[0]) << 16,
_ => 0,
};
let output_chars = chunk.len() + 1;
for i in 0..4 {
if i < output_chars {
let shift = 18 - i * 6;
let temp = buffer >> shift;
let index = (temp & 63) as usize;
encoded.push(BASE64_CHARSET[index]);
} else {
encoded.push(b'=');
}
}
}
String::from_utf8(encoded).map_err(Base64Error::Utf8Error)
}You’ll notice there’s a map_err function with our return statement, and again we have that Result custom error of type Base64Error.
The process of decoding is relatively straightforward once we’ve implemented encoding.
Since we’ve already covered the function signature with our custom Result return type, let’s get started.
Before we get the first character of the input, we’ll set up some variables to use.
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn decode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut decoded = Vec::new();
let mut buffer = 0u32;
let mut bits_collected = 0;
String::from_utf8(decoded).map_err(Base64Error::Utf8Error)
}
}The first two are the same as they were in our encode function, with one being the holding the decoded string, and the other a buffer to temporarily hold the values we’re working with. The last will be used to count how many bits we have collected, and to check whether we have 8-bits we can turn into a byte or not.
Now we can begin through our character string, only ignore the padding, which are denoted by the equal sign:
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn decode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut decoded = Vec::new();
let mut buffer = 0u32;
let mut bits_collected = 0;
for c in input.chars() {
if c != '=' {
}
}
String::from_utf8(decoded).map_err(Base64Error::Utf8Error)
}
}The next thing we’ll need to do is the verify that the index of our character is in the BASE64_CHARSET array, and we’ll do that by iterating over the array and grabbing the correct index. We could do this better with a HashMap, for our purpose it’s likely not much quicker.
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn decode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut decoded = Vec::new();
let mut buffer = 0u32;
let mut bits_collected = 0;
for c in input.chars() {
if c != '=' {
let position = BASE64_CHARSET.iter().position(|&x| x == c as u8);
}
}
String::from_utf8(decoded).map_err(Base64Error::Utf8Error)
}
}This is the opposite of what we did during encoding. To do that we make use of iter which is a shorthand way of looping through the array. On each iteration we return the position of our character. This code might be a little confusing if you haven’t seen chained functions like this, but think of it iter and looping and on each loop is runs the attached position function which only returns if the condition is met. The variable position will actually be an Option, we’ll next need to match on it.
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn decode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut decoded = Vec::new();
let mut buffer = 0u32;
let mut bits_collected = 0;
for c in input.chars() {
if c != '=' {
let position = BASE64_CHARSET.iter().position(|&x| x == c as u8);
match position {
Some(pos) => {
}
None => return Err(Base64Error::InvalidCharacter),
}
}
}
String::from_utf8(decoded).map_err(Base64Error::Utf8Error)
}
}You can see the first match arm is Some(pos) where pos represents the valid index. If it’s not a valid index, meaning position is None, we return an Err noting that the letter was not part of Base64. This corresponds to the line in our function definition where we return an i32 as part of the Result.
Appending to our buffere will use the same shifting strategy we used in encoding:
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn decode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut decoded = Vec::new();
let mut buffer = 0u32;
let mut bits_collected = 0;
for c in input.chars() {
if c != '=' {
let position = BASE64_CHARSET.iter().position(|&x| x == c as u8);
match position {
Some(pos) => {
buffer = (buffer << 6) | pos as u32;
bits_collected += 6;
}
None => return Err(Base64Error::InvalidCharacter),
}
}
}
String::from_utf8(decoded).map_err(Base64Error::Utf8Error)
}
}In doing this we first use the left shift « to push on the 6-bit chunk from our Base64 string into our buffer. Next, we use a while loop, though we probably could use an if statement just the same, and get the byte we want to convert.
We also save how many bits we’ve collected, because when we have 8 or more we’ll want to convert it to a byte.
Getting back to our match statement, let’s fill in the first arm with the details:
impl Base64 {
pub fn new() -> Self {
Base64 {}
}
pub fn decode(&mut self, input: &str) -> Result<String, Base64Error> {
let mut decoded = Vec::new();
let mut buffer = 0u32;
let mut bits_collected = 0;
for c in input.chars() {
if c != '=' {
let position = BASE64_CHARSET.iter().position(|&x| x == c as u8);
match position {
Some(pos) => {
buffer = (buffer << 6) | pos as u32;
bits_collected += 6;
while bits_collected >= 8 {
bits_collected -= 8;
let byte = (buffer >> bits_collected) & 0xFF;
decoded.push(byte as u8);
}
}
None => return Err(Base64Error::InvalidCharacter),
}
}
}
String::from_utf8(decoded).map_err(Base64Error::Utf8Error)
}
}To summarize what this loop is doing:
I want to clarify this part, though, which may be somewhat confusing:
bits_collected -= 8;
let byte = (buffer >> bits_collected) & 0xFF;By first subtracting 8 from our bits collected, and then shifting the remaining over, we’re grabbing the leftmost 8-bits from the buffer. The masking of & and 0xFF (11111111 in binary) ensures that we only get those 8-bits. This is similar to the masking we did earlier in encoding.
We’ll do this for everything in our Base64 string and then return an Ok( …) at the end which includes our decoded String type as a Result or an error, depending of it can be converted.
At this point the code is functional and we’ll be able to use it in later parts of this project. I’d encourage you to play with it a bit and try to add more tests and look at potential ways it could break.
Holy hell, that was a long one. I hope you got something out of this. I hope you learned something like I did. If you have questions or comments, feel free to email me at:

