This post follows from the first part where we talked a bit about APIs.
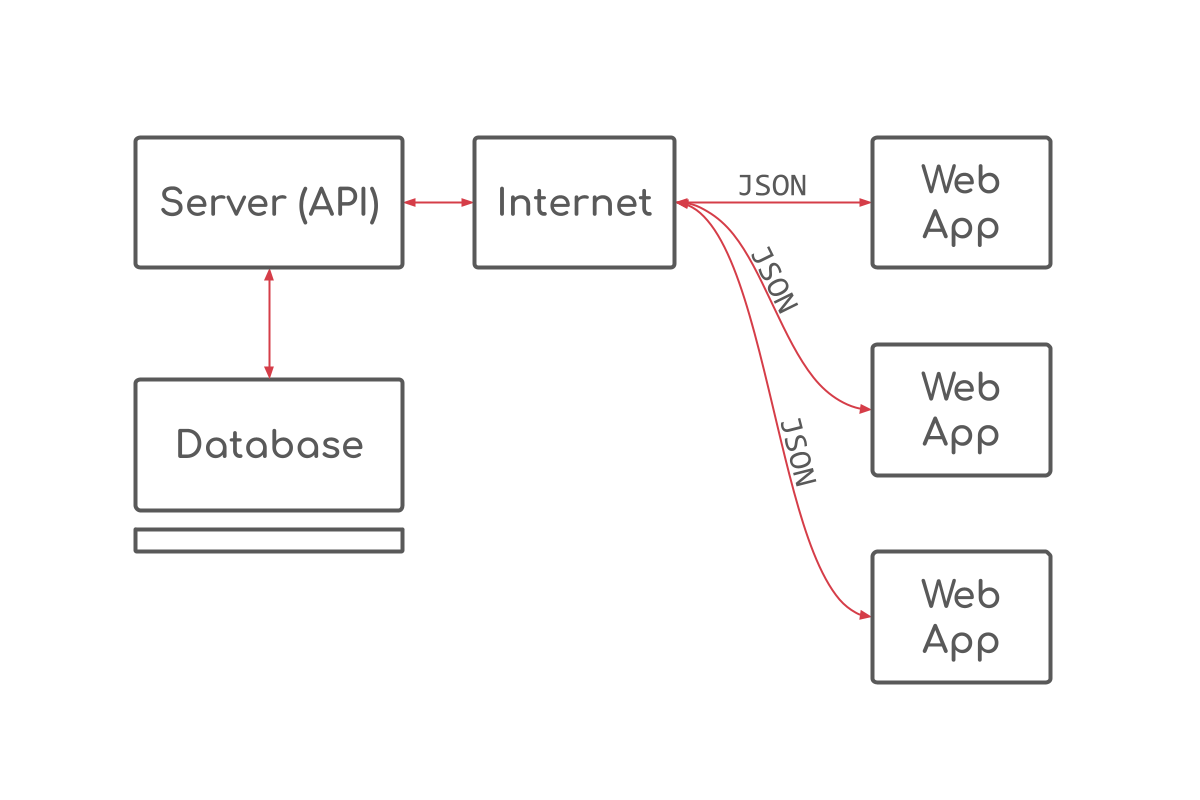
There are a number of constraints which make a REST API truly a REST API, and this site along with the Roy Fielding post mentioned previously, covers them in detail. A nice high-level overview can be found at How I explained REST to my wife, but to summarize, a RESTful API will meet the following terms:
How these are implemented is up to you, but these days it’s most often using HTTP and JSON. You have multiple clients (users using your app/site), sending requests (well-formed requests, mind you), which are handled by the server, usually backed with a database that stores the items using a unique id, like a primary key (persistent identifier).
I tend to work better when I see actual code, so let’s look at a simple unsecured API. All it will do is send back album titles when given an id.
As a reminder, these are my notes, and may contain errors. I can’t guarantee what I’m doing will meet Fielding’s standards of a RESTful API, hence the API’ish in the title, but it should be close enough that you’ll learn something.
In the server/src/bin folder of the repo you’ll find simple-api-1.rs. The program starts with the code snippet as shown below, and loads the database at the location found via the environment variable in the .env file. This file is found in the root of the server folder.
We use this method since the sqlx library requires access to the database to ensure we’re using the right types, and it looks in the .env file for its location. Here I use the dotenv crate to allow our server to recognize that an env file is present and to load it.
#[actix_web::main]
async fn main() -> std::io::Result<()> {
dotenv().ok();
let db_path = env::var("DATABASE_URL").unwrap();
let pool = SqlitePool::connect(&db_path).await.unwrap();
HttpServer::new(move || {
App::new()
.service(index)
.app_data(web::Data::new(pool.clone()))
})
.bind("127.0.0.1:3000")?
.run()
.await
}Below we create our route so that our frontend can query the album information. This route takes a u32 from the URL path and looks up an album by id.
I’ve avoided explicitly handling errors, and instead use unwrap for the sake of brevity, though in a normal situation you’d want to provide the user with appropriate responses for invalid requests. An invalid request in this case would be something like not using a u32 for the id or an invalid id. Note that using unwrap along with the default error messages that Actix provides could lead to security risks if those messages expose information about your database or setup which a malicious party could take advantage of.
|
|
Actix has what’s called extractors that come as optional parameters to a route. Here we have used Path and Data of an SqlitePool, type. This allows us to check the URL path for the id, as well as provides access to our database pool. We then query the database using the connection aquired from the pool via the query_as! macro^1.
Note that we should probably have used fetch_one here. In revising this document I’m not sure why I used fetch_all, but it’s possible that at the time there was something with sqlx that made that difficult or perhaps incompatible with the query_as! macro.
The results are then serialized using the serde_json library and converted to a string. The HttpResponse will wrap the serialized JSON result, adding the appropriate HTTP headers, such as the HTTP 200 OK, indicating success.
To see all this take place, from the server folder of the repo, run the following:
$ cargo run --bin simple-api-1After it snags all the dependencies you’ll be rewarded with mostly empty nothingness and a surge of existential dread that makes you wonder why you’re reading about APIs instead of out enjoying a nice hike through woods. Once that passes, open your browser and navigate to http://localhost:3000/albums/43 and you should see the following:
[{"album_id":43,"title":"MK III The Final Concerts [Disc 1]","artist_id":58}]To summarize what we just did, we’re using the HTTP protocol to make a GET request, and the route handler, which we’ve called index, is pulling parameters from the URL path. Those value should u32 type (an unsigned, aka positive integer) and correspond to a valid album id in our database. This album is queried using sqlx and the result is cast to a string before being returned.
You can further test this by changing 43 to a string, such as HI, and you should get an error:
can not parse "notanint" to a u32This is a fairly high-level view of what’s happening. For starters, we don’t see any of the details of the HTTP request. I promise it’s there, but we’ve let Actix handle it, though we can see what it looks like by adding an additional extractor to the index route.
You can do this to the current simple-api-1 file or just run simple-api-2 which has the following changes in place.
|
|
Run using:
$ cargo run --bin simple-api-1The output should look something like the following:
HttpRequest HTTP/1.1 GET:/albums/43
params: Path { path: Url { uri: /albums/43, path: None }, skip: 10, segments: [("id", Segment(8, 10))] }
headers:
"sec-fetch-site": "none"
"sec-gpc": "1"
"accept-language": "en-US,en;q=0.9"
"sec-ch-ua-mobile": "?0"
"user-agent": "Mozilla/5.0 (X11; Linux x86*64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/\_;q=0.8"
"sec-ch-ua": "\"Brave\";v=\"107\", \"Chromium\";v=\"107\", \"Not=A?Brand\";v=\"24\""
"sec-fetch-dest": "document"
"host": "localhost:3000"
"sec-ch-ua-platform": "\"Linux\""
"cache-control": "max-age=0"
"connection": "keep-alive"
"accept-encoding": "gzip, deflate, br"
"sec-fetch-user": "?1"
"upgrade-insecure-requests": "1"
"sec-fetch-mode": "navigate"This touches on the self-descriptive part of what makes it RESTful. It has everything our server needs in order to process the request. It then returns a similar looking response to us, which you can see if you open the developer tools in your browser and look under the network tab below headers (I’m using a Chrome-based browser and FireFox may be slightly different).
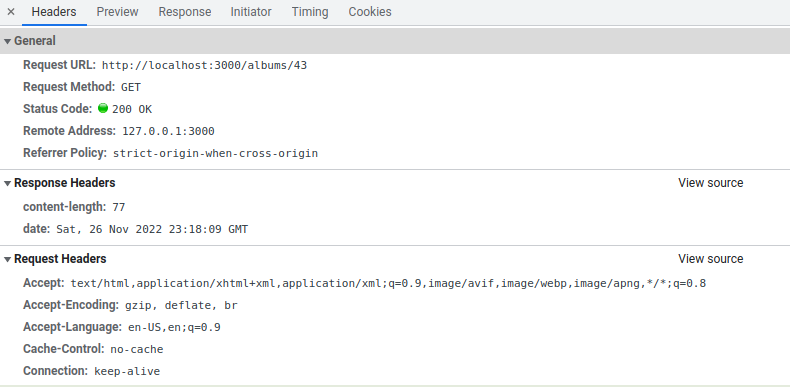
For the most part this works fine for what we’re doing, but from a real world perspective it’s pretty bad. There’s no monetization, Google analytics, or even a blockchain, which means we’re hardly even at Web 2.0. That aside, the real issues come from it not being accessible via a frontend, nor having anything setup to keep it secure once we do.
We can see why this by running the client I’ve included in the client folder under simple-client. Inside the folder you’ll find an HTML file, stylesheet and some JavaScript. To run the server you’ll need Python or some equivlant way to run the server:
$ python -m http.serverThen head over to http://localhost:8000, type in an ID, or use the default 43, and prepare to be disappointed. Nothing should happen. Open your developer tools and you should see an error that reads something like:
Access … has been blocked by CORS policy: Response to preflight request doesn’t pass access control check: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.
Which leads us to the next question of What is CORS? and why does it stop our client from reaching our API?
Referenced links

