The Word2Vec model is one of the better known methods for creating word embeddings, aka a bunch of vectors from which we can infer relationships within our data. If you’re not sure I mean by any of that, read the links in the last sentence and then mosey on back, otherwise, read on.
It will probably help if we have some idea of what we’re trying to achieve by doing this. The general idea is that we want to create a machine learning model (ML model) which understands and generates text. With luck, that text will be more than gibberish, and possibly even useful to us.
Maybe we want something that can help us screen emails for spam, or perhaps we’re aiming higher, and trying to create a large language models like ChatGPT, Claude or Llama. It doesn’t matter at what level we’re building, we’ll likely follow a few steps (zooming out to extreme abstraction):
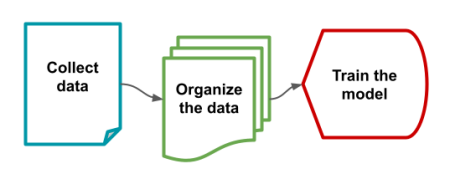
What Word2Vec does is at the organize data level. It’s not the model itself. It’s what we do before we even starting training a model.
But what sort of data are we talking about? In modern machine learning we could be talking about almost every freely available piece of text online, the entire Library of Congress, or all of Reddit. Before we train anything we need to organize this data into something that our ML model can easily digest, and that’s where Word2Vec comes in. It will take an entire corpus (body of text) and assign every word, or token, a three-hundred dimensional vector (dimensions may vary).
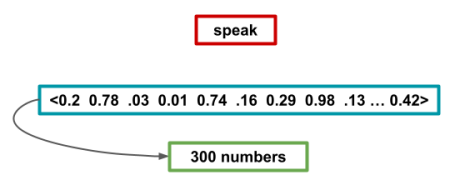
You’re probably thinking that trading a simple word like erinaceous for a vector with 300 numbers in it sounds like a bad trade. You might also be thinking why in the hell would I do any of this, and why can’t I just shove all my text through the ML model? Well, as discussed in the post on embeddings, ML models are picky on input size, for one, and for two, we get some added benefits from turning everything into a vector.
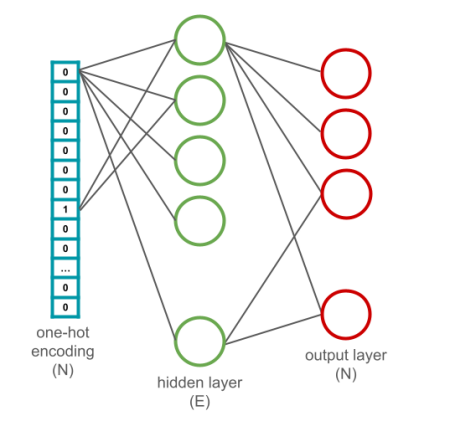
How Word2Vec takes all this text and converts it into these vectors is deceptively simple. We first take all unique words from our corpus and create (one-hot encoded)(../one_hot_encoding) vectors. Let’s say there are N unique words. Then we create a neural network with one hidden layer that is 300 nodes in size (this can vary), and an output layer which is the same N as the input where each output node matches one of the unique words.
To train using Word2Vec we’re going to read through our entire corpus. We’ll be doing that using something referred to as a window. What that means is we pick a word and look at the words around it. If the window size is two, we look at two words to the left and right of the chosen word. Below the chosen word is ate.

In the case of ate the window include four other words, as highlighted above: unspeakable, pear, the, and cat. We’re going to use these words to try and predict our chosen word ate. We could use all the context words, but it’s probably more common to randomly pick a subset of them. Let’s say we pick pear and cat.
We now run pear and cat through our network, trying to get the word ate back. This is how relationships are built over time. It’s also why need a large corpus, because we want to capture the word ate in as many possible contexts as possible.
After running our entire corpus through this neural network, we now want to get our vectors. We take each of our unique words (the one-hot encodings) and send them in as input one more time, but instead of running it all the way through, we prematurely extract the values from the hidden layer after summation but before activation. Since there are 300 hidden layer nodes, we take the values from those and it is the vector for whatever word’s one-hot encoding we just input. Repeat for every unique word in your corpus and save those vectors in your lookup table.
What we get from this is:
And that’s about it. We can now use these embeddings as a way to look up the context of every word in our corpus. It allows us to find similar words, opposites and even use arithmetic operations between the vectors to find associations. Neat.

