The word token, at the bare minimum, is a unit of data. In the majority of cases you’ll come across, it will refer to textual data within natural language processing (NLP). In this context, token may refer to a single word or part of a word. For example, you could use the word unadulterated as a single token or break it into pieces like un-adulterat-ed or something similar to that.
How words are split depends on the morphology of the language.
morphology (mor-FOL-ə-jee) is the study of words, including the principles by which they are formed, and how they relate to one another within a language.
Morphology is part of linguistics, and is far too broad a topic to dive fully into here, but there are some terms you may encounter when reading through machine learning and NLP related texts, and those word-form, morpheme and lexeme.
A word-form is just a word, the same as you’d speak or read, while a morpheme can be a part of a word. For example, the word swimmingly is itself a word-form, while swim, ing and ly are different types of morphemes. The word swim is referred to as a free morpheme (you may also hear the word root morpheme in a similar context, though it’s something somewhat different), because it can stand as a word by itself.
If you wanted to break a text into tokens, a process known as tokenization, you could use just the whitespace and do something like:

But within this, you could break some words down into morphemes:
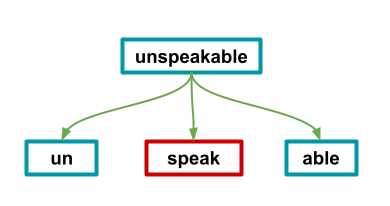
The last term, lexeme, is another term for a free morpheme. They are standalone words which are considered the basic unit of a group of word forms. For example, run is part of running, ran, runner, and other similar words.
While the word token most often refers to words or word parts, it can be found within the field of AI outside of using textual data, though it’s less common. You can, for example, find it being used to refer to image and sound data, as well as other information.

